DeepSeek-模型(model)介绍
发布时间:2025-04-23 编辑:游乐网
我们已经部署过windows版本、linux版本、单机版本和集群版本,并且在过程中使用了多个模型。那么,这个模型到底是什么呢?你可以选择哪些模型呢?什么是蒸馏版、满血版和量化版呢?
首先,我们需要理解什么是训练模型和推理模型。
训练模型
训练模型是指模型在学习阶段的过程。在这一阶段,模型通过大量标注数据(输入数据和对应的标签/答案)逐步调整内部参数(如神经网络的权重),目标是学习数据中的规律,从而能够对未知数据做出预测或分类。
国产大模型DeepSeek之所以火爆,是因为它以较低的成本(500万美元以上)训练出的模型达到了ChatGPT等闭源模型的性能。DeepSeek将训练的模型开源并允许商用,目前国内许多厂商都使用DeepSeek的67B模型来供普通用户使用。
注:这里的B指的是参数,参数越大,代表能力越强,一个B代表10亿参数。
推理模型
推理模型是指训练完成后,模型应用阶段的过程。此时模型参数已固定,用于对新的输入数据(未见过的数据)进行预测或分类。我们前面搭建的所有大模型都是使用DeepSeek开源的模型搭建的。
蒸馏模型
DeepSeek到目前为止开源的模型有多个,其中最火爆的是DeepSeek-R1,因为它不仅发布了67B的满血版,还发布了蒸馏版。通过知识蒸馏技术将DeepSeek-R1(参数量67B)的推理能力迁移至更小的模型中。可以简单理解为蒸馏版比原始版本更厉害。

目前这些模型可以在多个大模型框架中使用(包括我们讲过的ollama和vllm,甚至未讲过的sglang等)。
量化模型
虽然这些模型对原始模型进行了蒸馏,但对于GPU的要求仍然较高。对于ollama框架来说,模型仍然较大,因此ollama对这些模型进行了进一步量化。以1.5模型为例,默认格式是fp16,原始大小是3.6G,量化一次可以降低接近50%的大小,也相对降低对显存的需求。

显存需求
此图是我从互联网找来,仅供参考。

实测ollama运行deepseek-r1:32b-qwen-distill-q8_0模型,显存占用在40G左右。
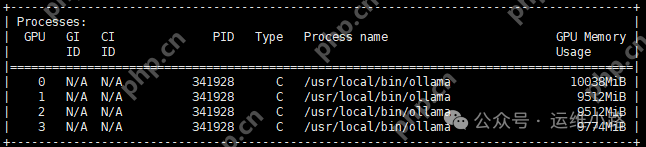
vllm运行deepseek-ai/DeepSeek-R1-Distill-Qwen-14B和deepseek-ai/DeepSeek-R1-Distill-Qwen-32B模型,显存占用都是到116G(vllm会按照显存的90%去计算剩余显存,当模型等资源加载完成以后剩下的都会用作缓存)。
代码语言:javascript代码运行次数:0
运行复制```javascript(VllmWorkerProcess pid=195) INFO 03-09 10:10:40 worker.py:267] model weights take 15.41GiB; non_torch_memory takes 0.14GiB; PyTorch activation peak memory takes 0.24GiB; the rest of the memory reserved for KV Cache is 12.76GiB.```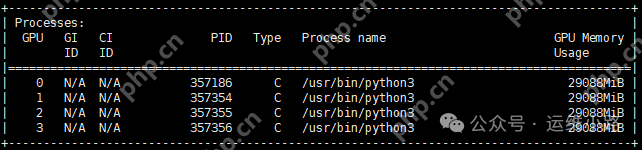
相关阅读
MORE
+- 锁定网络攻击怎么解除 04-24 微软笑开花!Windows 10市场份额再次增加 04-24
- 一文读懂!DeepSeek 与 Dify 打造 AI 应用实战指南 04-24 深度告诉你100年都不用更新的操作系统 04-24
- 腾讯云 AI 代码助手 上新tencent:DeepSeek 模型 强烈安利 04-24 谷歌浏览器官网入口在哪-谷歌浏览器官方入口链接是啥 04-24
- DeepSeek R1后,AI应用、职业与行业! 04-23 基于腾讯云HAI-CPU部署DeepSeek:搭建图书馆知识库,赋能智慧图书馆建设 04-23
- DeepSeek如何轻松搞定Excel公式(附3个实战案例) 04-23 DeepSeek-单机多卡折腾记 04-23
- 精彩!!!Deepseek 重写 K8s 故障处理案例,文笔真好,屌~ 04-23 DeepSeek-模型(model)介绍 04-23
- 192.168.103登录入口 192.168.103登录页面进入 04-23 谷歌浏览器怎么设置中文-谷歌浏览器设置中文的方法 04-23
- 统信操作系统V20龙芯版正式发布:自主指令集、能用微信/PS 04-23 教你winscp使用教程 04-23
- Linux 5.17内核全力优化AMD锐龙:Zen4准备好了! 04-23 深度操作系统deepin 20.4发布:升级Linux 5.15内核 04-23




























 湘公网安备
43070202000716号
湘公网安备
43070202000716号